
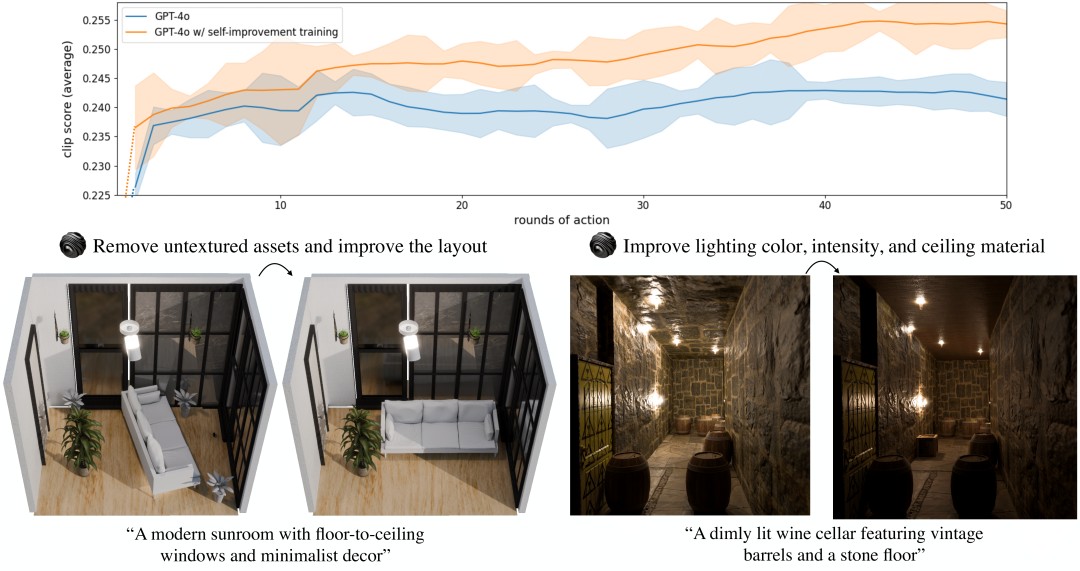
Jensen Huang’s trillion dollar dream just came true. NVIDIA has released its version of a world model. While Sora makes videos, NVIDIA makes 3D worlds. This is not just about watching AI generate clips. This is about AI that can build, modify, and interact with entire 3D universes in real time. The possibilities are endless.
Jensen Huang is not joking around.
When AI can only watch videos and speak, it is just a spectator. But when AI can understand and change the physical world, everything changes.
Now, NVIDIA has filled in the most critical missing piece.
They are turning AI from a video watcher into a world builder. AI can now generate fully interactive 3D worlds. It can build rooms, modify scenes, and interact with objects.
Time rolls back to February 2024.
OpenAI released a stunning video called Sora. It shocked the world with its hyper-realistic scenes.

But the high-end realism also exposed a fatal flaw. Sora is a video generator. It cannot interact with the world.
In a snowy scene, a woman walking on the street leaves footprints. But if you throw a snowball at her, nothing happens.
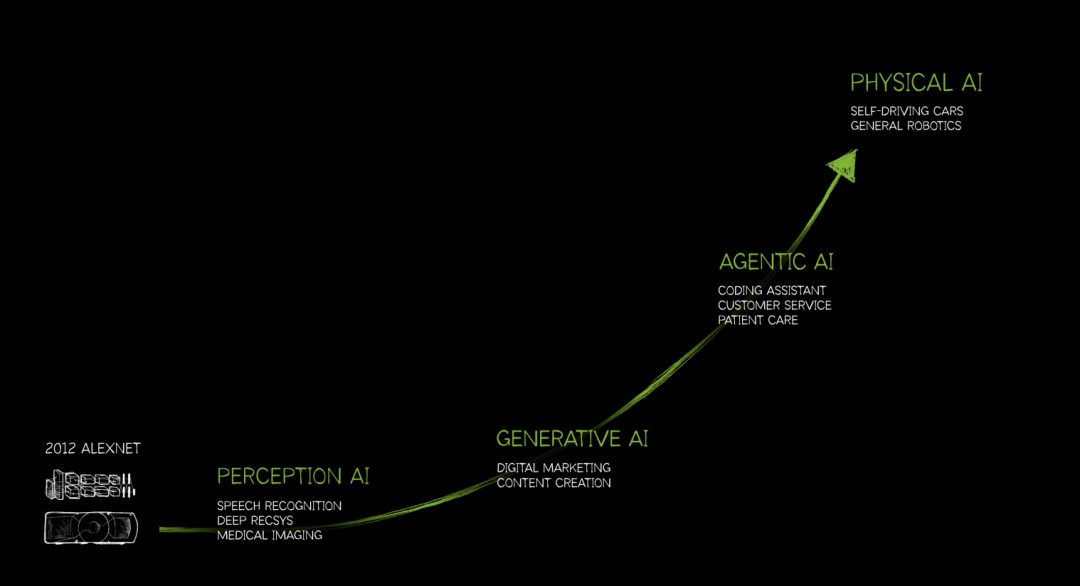
In multiple speeches from 2024 to 2025, Jensen Huang repeatedly emphasized a concept called Physical AI.

Click to view full image
The fatal flaw of video generation models is this.
AI-generated videos are just projections of the physical world onto a flat screen. They are one-way. You can watch but you cannot touch.
There is no gravity, no friction, no collision.
They are not worlds. They are just video clips. If a person walks out of the frame, they are gone. porn ai chat That is not AI. That is just animation.
At the time, many people thought Jensen Huang was just selling GPUs. They thought his goal was to promote the Omniverse platform and RTX graphics cards.
Until CES 2026, people finally understood what he meant.
celebrity ai nudes
Recently, NVIDIA quietly released a paper. It is not just a paper. It is a 3D world model.

Paper link: https://research.nvidia.com/publication/2026-03_3d-generalist-vision-language-action-models-crafting-3d-worlds
People say ChatGPT taught AI to speak. They say Sora taught AI to see. But what NVIDIA’s world model teaches AI is to understand the world.
Computer vision has won the battle for pixels. But this is just the eve of true intelligence.
Jensen Huang has not stopped.
He is waiting for the ChatGPT moment of AI. And now, it is officially here.

 NVIDIA Releases Paper That Changes Everything
NVIDIA Releases Paper That Changes Everything
This paper comes from NVIDIA and Stanford University. It was officially released at the top computer vision conference CVPR 2026.
The title is 3D Generalist Vision-Language-Action Models for Crafting 3D Worlds.

From March 20 to 23, 2026, at the top computer vision conference CVPR in Nashville, Tennessee, this paper was officially presented.
The core contribution is not just the technical details in the paper. It is a key word that people must remember.
Action. That means doing.
This is a breakthrough in logic.
In the past few years, AI tools like Midjourney for images and Runway for videos played the role of observer and creator.
You give it a photo of a cat. It generates a video based on your prompt, predicting what color the cat should be and generating a cat video.
But it does not know if cats have bones. It does not know if cat fur has texture. It only knows about video signals.
Now, NVIDIA’s VLA or Vision-Language-Action model has broken through this logical barrier for the first time.
It is not just watching. It is a generalist.
As long as you say 3D Generalist, it means a model that understands all aspects of 3D.
These 3D aspects include layout, fixed furniture, movable objects, and openable 3D assets and their functions.

More importantly, this model can understand fine-grained text descriptions. It knows what a 3D scene should look like as a whole, not just individual objects.
In other words, by using large-scale 3D asset data, they continuously improve and optimize these 3D scenes.
In their experiments, a key module is fully automated generation.
As shown in Figure 2, their model can generate an initial 3D scene from text. This includes layout, fixed furniture, movable objects, and openable items.
To avoid the problem of traditional methods oversimplifying or deviating from reality, they use a full diffusion model. They first generate a 360-degree panoramic image as guidance, then reconstruct the 3D scene through inverse graphics.
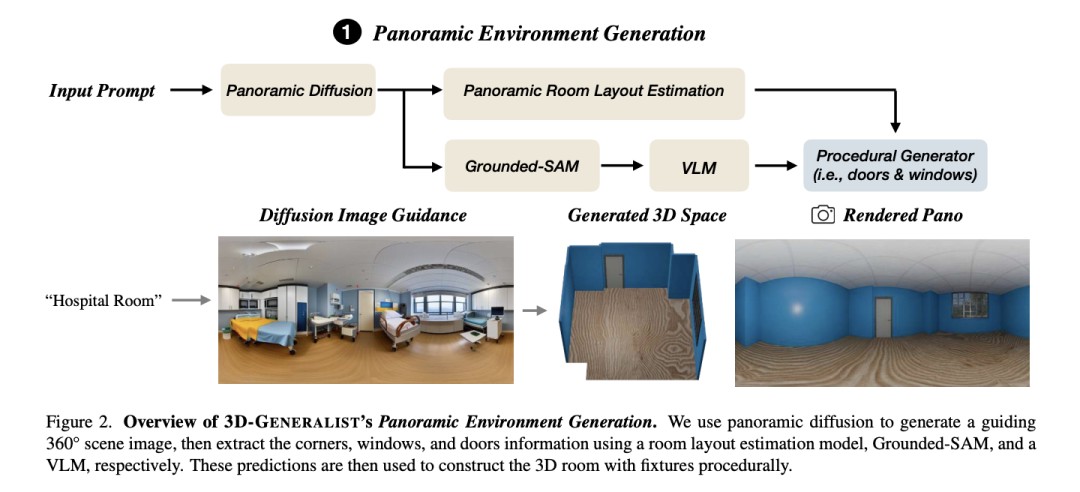
Figure 2: 3D Generalist fully automated generation pipeline. Full diffusion model generates 360-degree scene images, then uses Grounded-SAM visual segmentation model to extract room, object, and position information. These predictions are fused through simplified methods to generate a complete 3D scene.
The entire workflow includes the following steps.
First, 3D Generalist uses a diffusion model to generate panoramic images, then reconstructs the 3D scene structure through inverse graphics.
Second, 3D Generalist uses a Vision-Language-Action or VLA model to generate code for creating and modifying 3D scenes, including materials, layout, and asset placement.
Third, this VLA improves scene details through an iterative refinement training loop, optimizing the effects of text prompts.
Fourth, 3D Generalist uses a unified VLA model for all tasks, even when 3D assets are unlabeled.
After fine-tuning, 3D Generalist shows amazing capabilities.
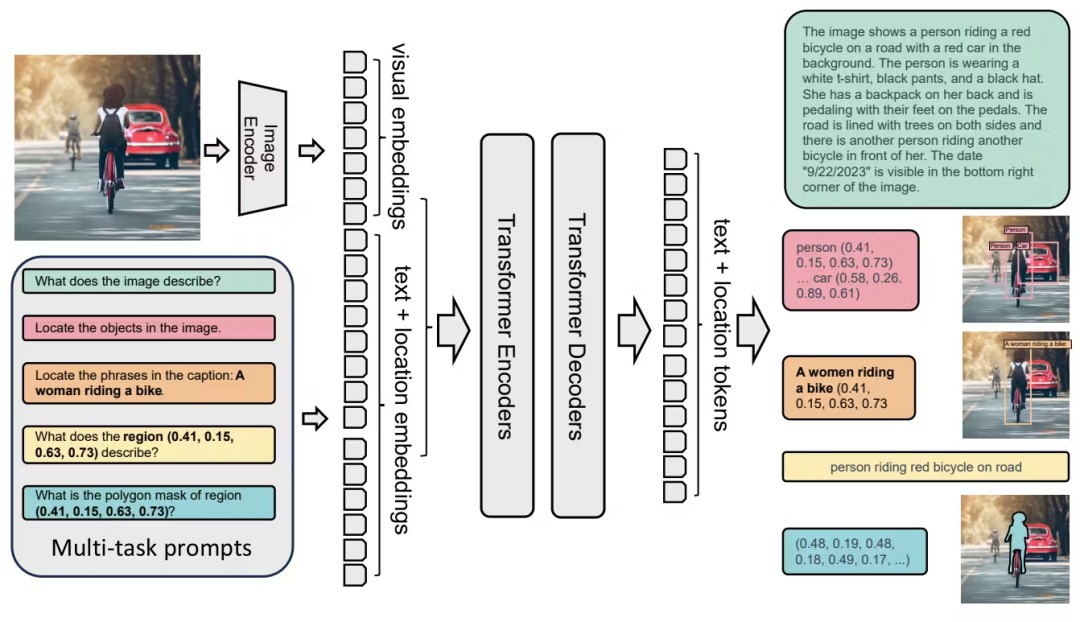
The research team also used Florence-2 to synthesize training data for 3D scenes generated by 3D Generalist, training a visual segmentation model.
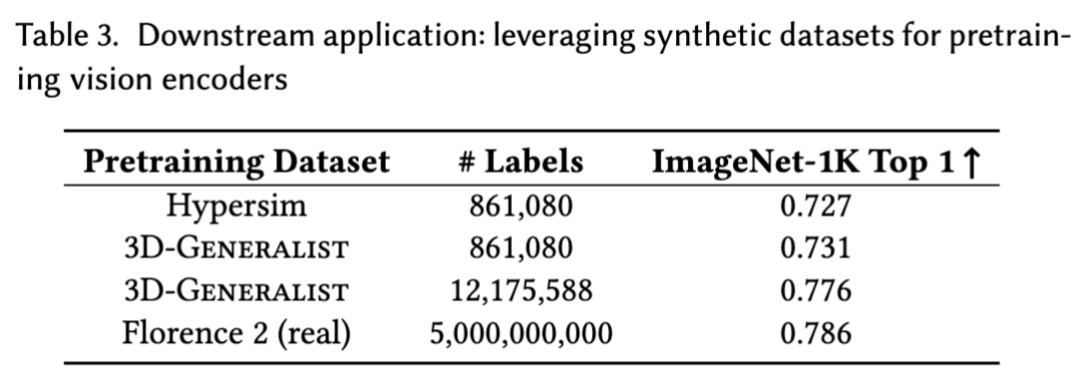
The final results show that using a public model with almost no training, they achieved remarkable results.
 Physical AI ChatGPT Moment Has Arrived
Physical AI ChatGPT Moment Has Arrived
Some people think Jensen Huang is just selling GPUs. They think he only cares about game graphics and visual effects. But they underestimate NVIDIA’s ambition.
NVIDIA is not just making game graphics cards. They are building the physical intelligence of the future.
The core battlefield of this paper is embodied AI. This is NVIDIA’s most important strategic layout.
Jensen Huang has long emphasized that the next trillion dollar opportunity is embodied AI.

Let us look at the logic behind this.
If you want a general-purpose robot, whether it is Tesla’s Optimus or NVIDIA’s Project GR00T, the robot needs to learn.
It needs to learn how to grab a cup, how to wipe the floor, how to walk on the road.
But in reality, training robots is too slow and too dangerous. You cannot let a robot fall a thousand times in a real factory. You cannot let an autonomous car crash a thousand times on a real road.
So the solution is to train them in a virtual world first.
But the problem is that current world models cannot build realistic enough virtual worlds.
When a model generates a room, the physics of that room are fake. A cup placed on a table might float. A ball might roll through a wall.
Now, with the 3D Generalist model, NVIDIA has combined world models with 3D communication for the first time.
This means that the virtual worlds generated by NVIDIA are no longer just visual fakes. They are real physical simulations.
In these generated 3D worlds, a robot can practice walking millions of times without falling once. Because the physics are real, the training is real.
Within NVIDIA’s Omniverse ecosystem, research teams use Omniverse Replicator to create synthetic training data. It supports domain randomization. Isaac Lab provides a ready-to-use robot training environment, including humanoid robots. These generated worlds are used for reinforcement learning training.
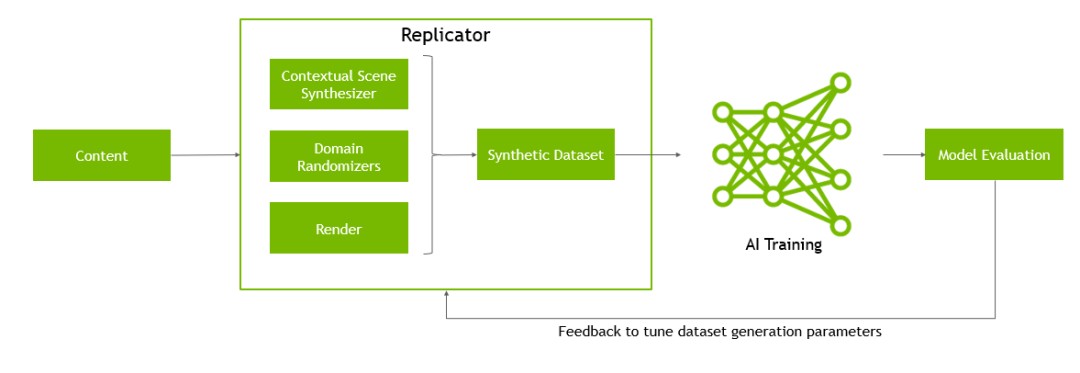

This is the ultimate goal of Physical AI. To achieve sim-to-real transfer. From simulation to reality in one step.
Jensen Huang’s layout is not just a generated world. It is a complete physical intelligence ecosystem.

Everything That Moves Will Be Autonomous
From language models that understand text, to video models that understand images, to physical AI that understands the world. The evolution of AI has reached a new stage.
When AI can create virtual worlds and have real physics, it means movies and games will be completely transformed.
When AI can create virtual worlds and train real robots, it means the manufacturing industry will be completely transformed.
At SIGGRAPH 2024, Jensen Huang said, everything that moves will be autonomous.

At the time, people thought he was exaggerating.
Now it looks like he was being modest.
 Core Research Team
Core Research Team
Fan-Yun Sun

Fan-Yun Sun is a PhD student at Stanford AI Lab or SAIL. He leads the Autonomous Agents Lab and is also a member of the Stanford Vision and Learning Lab or SVL.
During his doctoral studies, he has also been a research intern at NVIDIA Research. His work focuses on efficient deep learning, visual perception research, Metropolis platform learning, Omniverse, and autonomous driving research.
His main research interests include generating 3D worlds from text, training generalist models and reinforcement learning agents, and developing multi-modal world models.
Shengguang Wu

Shengguang Wu is currently a PhD student in the Computer Science Department at Stanford University, advised by Serena Yeung-Levy.
He previously earned his master’s degree from Peking University, advised by Qi Su. He was also a research intern at the Qwen team at Alibaba.
His research focuses on multi-modal world models, reinforcement learning, and their applications in autonomous driving.
Jiajun Wu

Jiajun Wu is an associate professor in the Computer Science Department at Stanford University and also an associate professor in the Psychology Department.
Before joining Stanford, he was a visiting researcher at Google Research, advised by Noah Snavely.
He graduated with a bachelor’s degree from the Department of Electronic Engineering at Tsinghua University, advised by Zhuowen Tu. During his time at Tsinghua, he received multiple honors including the first-class scholarship and the Tsinghua University Special Prize. He also studied abroad at MIT and the University of Hong Kong.
He earned his PhD from the Massachusetts Institute of Technology, advised by Bill Freeman and Josh Tenenbaum.
Jiajun Wu’s team has published numerous papers in top computer vision and machine learning conferences. Their projects include Galileo, MarrNet, 4D Roses, Neuro-Symbolic Concept Learner, and Scene Language.
He and his team are exploring applications of these technologies in various fields.
Shangru Li

Shangru Li is a senior systems engineer at NVIDIA. He works on the IVA intelligent video analytics platform and the Metropolis platform.
He holds a master’s degree in Computer Graphics from the University of Pennsylvania and a bachelor’s degree in Software Engineering from South China University of Technology.
His work focuses on edge computing.
CADOAN is a professional, independent AI industry blog and information platform dedicated to the research, sharing, and popularization of artificial intelligence. We are a team of AI enthusiasts, researchers, and technical writers who focus on the development and application of modern artificial intelligence. We do not represent any commercial institution, technology company, or AI model camp. Our only position is to provide real, objective, and valuable AI content for readers, learners, developers, and business practitioners around the world.