
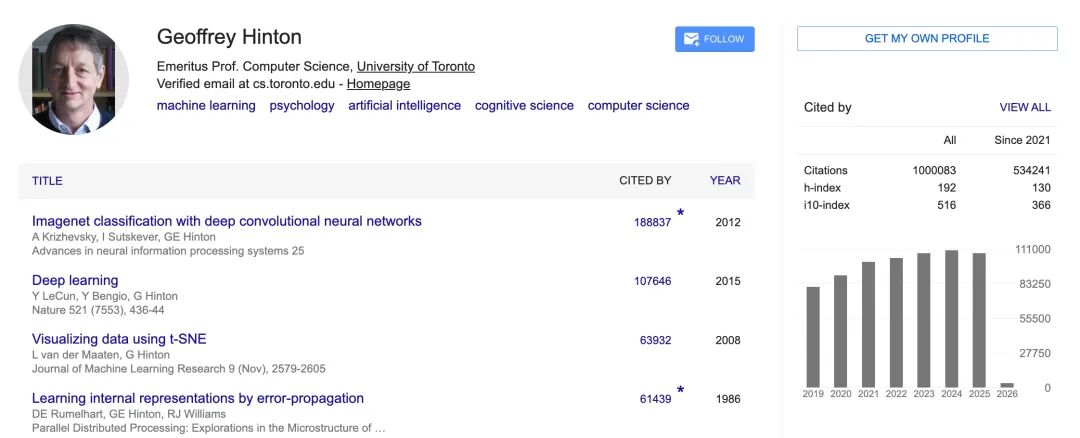
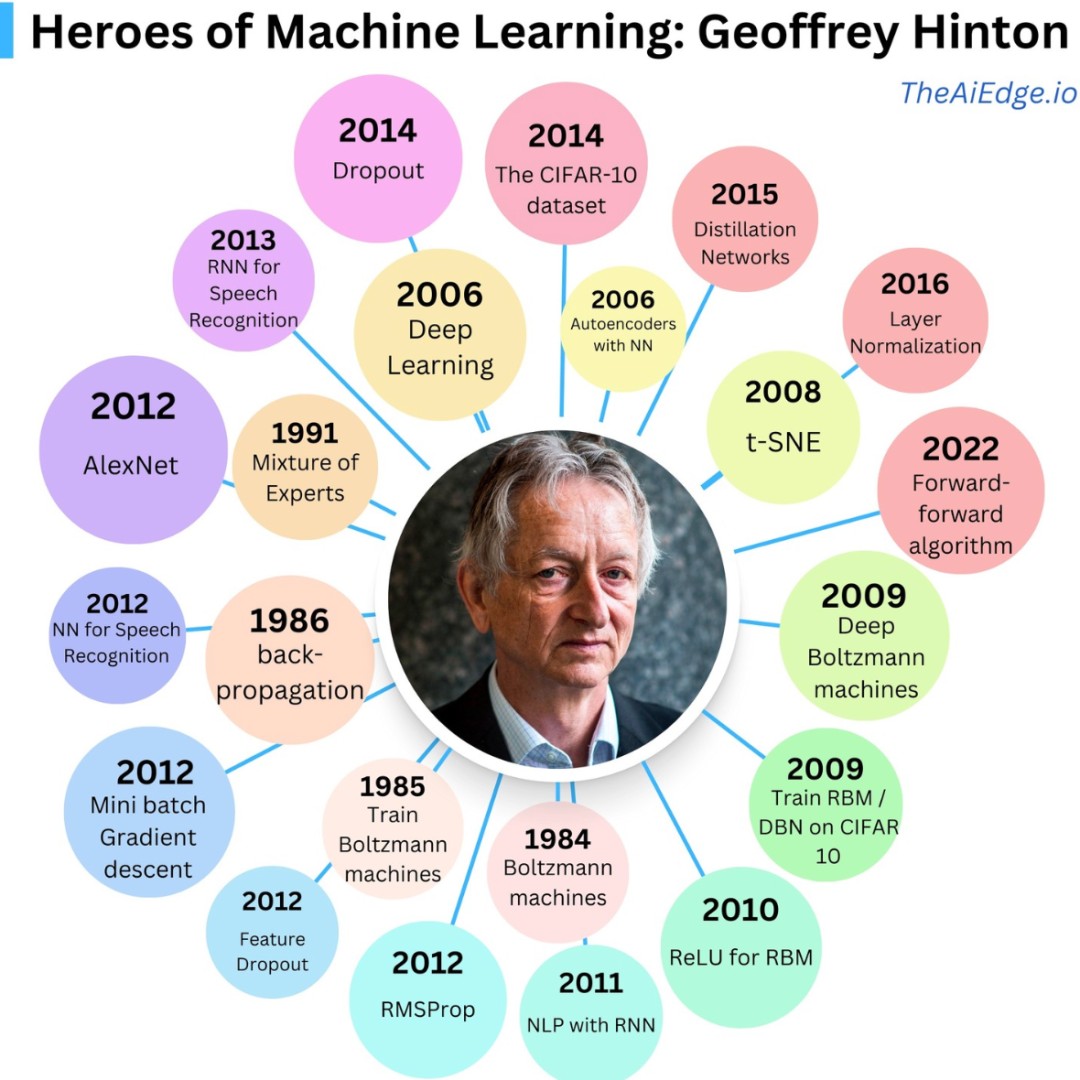
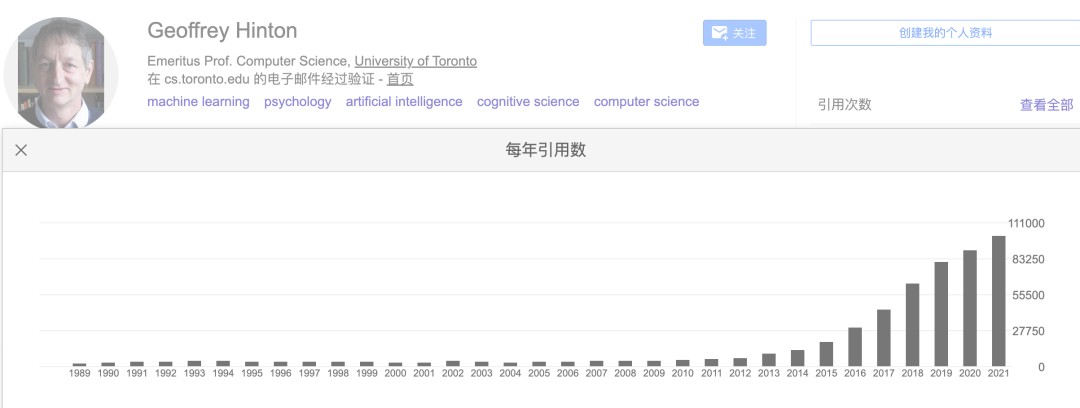
Geoffrey Hinton just made history again. His research papers have been cited one million times. He is now the second scientist in the world to reach this milestone, right after his fellow AI pioneer Yoshua Bengio. This is proof that the father of deep learning has shaped modern artificial intelligence more than almost anyone else alive.
This is a historic moment.
Recently, AI godfather and Turing Award winner Geoffrey Hinton officially crossed the one million citation mark.

He is the second person in the world after Yoshua Bengio to break through the one million citation barrier among living scientists.
This achievement is almost unbelievable.
 For a moment, the academic world was buzzing with celebration for Hinton.
For a moment, the academic world was buzzing with celebration for Hinton.
 The Second Person in the World
The Second Person in the World
Just a few days ago, Nature magazine reported that Bengio became the first living researcher to reach one million citations.
This record attracted massive attention in the AI and academic communities.

According to Google Scholar data, Bengio’s total citations have now reached 1.036 million.
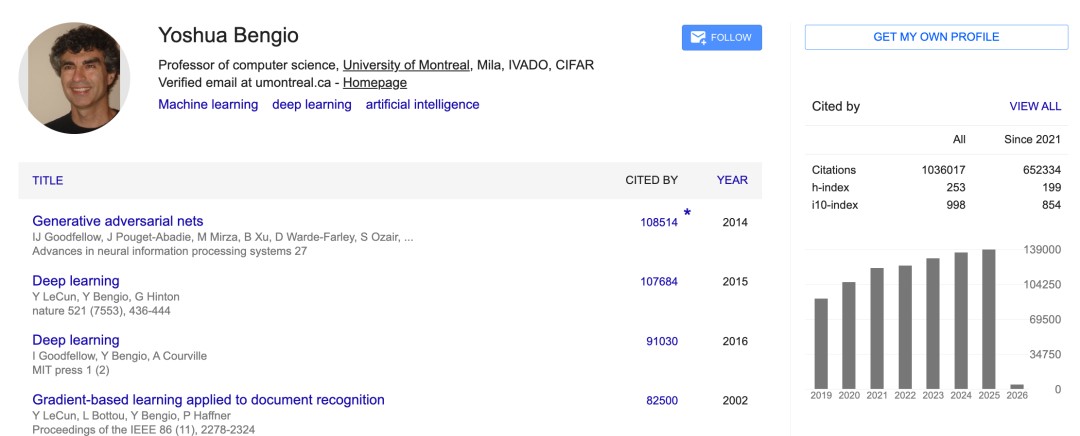
And now, Hinton has quickly followed, breaking through the one million mark almost at the same time.
The two men share the same foundational contributions to deep learning. Their ideas about neural networks and brain-inspired computing were once seen as fringe science. Now they are mainstream.

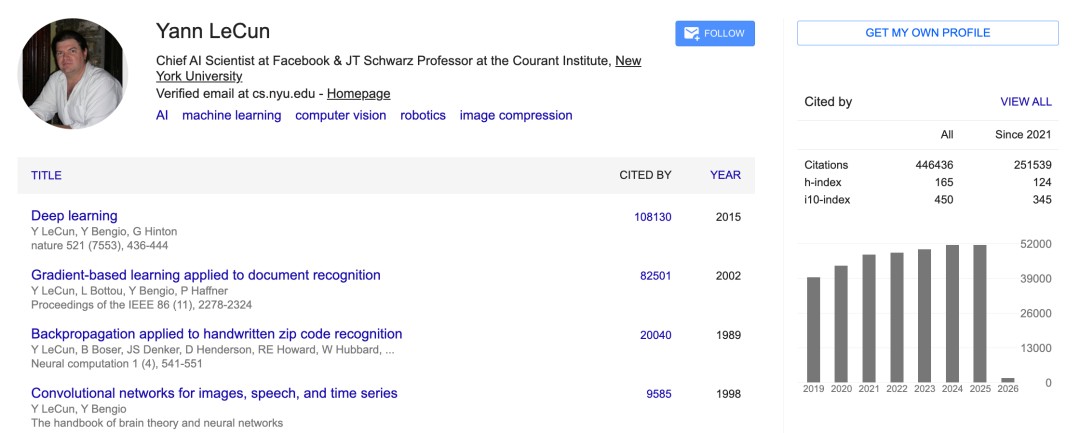
What is even more impressive is that fellow Turing Award winner Yann LeCun has also reached a terrifying 450,000 citations.

What One Million Citations Really Mean
At first glance, one million citations is just a number. But for researchers, it represents the entire history of machine learning development.
Hinton’s papers have had a strong cumulative effect. Many of his early works became the starting point for countless research projects.
AlexNet was the first deep convolutional neural network to win the ImageNet competition. It directly ignited the deep learning revolution in industry and academia.
More importantly, the combination of big data plus GPUs plus deep neural networks created a scalable approach. It allowed computer vision technology to begin serving different tasks using the same basic framework.

Deep learning is not a single technology. It is a unified paradigm that has spread across different research fields and achieved breakthroughs.
People began to ask why neural networks could be trained so well, what they learned, what they lacked, and what the key components were.
The t-SNE visualization research showed how models organize high-dimensional data. It revealed how categories form, how boundaries emerge, and why things cluster together.
These questions were once hidden inside black boxes. Now they can be directly observed through visualization tools.
Dropout was another major breakthrough. It randomly drops neurons during training, forcing the network to learn more robust representations and reducing overfitting.
For many people, the first time they encountered deep learning training, the core concept they learned was this.
These contributions share a common thread. They all answer the most fundamental questions about models. Not just providing answers, but explaining how to ask, how to verify, how to train, and how to improve.
In the AI wave, Hinton’s influence extends to the core of today’s large models like ChatGPT and Gemini.
Bengio, as the first to break the million mark, once said that without Hinton’s persistence, the academic status of deep learning might not exist today.
Recently, Hinton stated in a speech that large language models or LLMs do have some understanding. They are not just stochastic parrots that repeat what they have seen.
Their understanding comes from the need to predict the next word during training. To do this well, they must understand the context. To a large extent, they do.
However, as a pioneer in future AI research, he remains deeply concerned about potential risks.
 Academic Journey
Academic Journey
Hinton was born in London, England in 1947. His family was full of scientists. His father was a famous entomologist. His great-grandfather was George Boole, the founder of Boolean algebra and modern computer logic.
In 1970, he graduated from King’s College, Cambridge with a degree in experimental psychology. He then moved to the University of Edinburgh. In 1978, he earned his PhD under Christopher Longuet-Higgins, focusing on neural network models and machine learning.
During his career, Hinton taught at the University of California, San Diego, and Carnegie Mellon University. At that time, neural networks were seen as a fringe field. In 1987, he moved to the University of Toronto in Canada, where he taught until 2023.
During this time, he established the Neural Computation and Adaptive Perception Lab and trained many top AI talents.
In 2013, he joined Google as a vice president at Google Brain. He led industrial deep learning research and promoted breakthroughs in speech recognition and image classification.
Hinton’s core contributions span decades. His most important work includes the backpropagation algorithm, the restricted Boltzmann machine, and deep belief networks. In 2006, he used layer-by-layer pre-training to solve the gradient vanishing problem, reviving deep learning and leading to breakthroughs like AlexNet.
In 2018, Hinton shared the Turing Award with Yann LeCun and Yoshua Bengio. This is known as the Nobel Prize of computing. They were recognized for their conceptual and engineering breakthroughs that made deep neural networks a key component of computing.

In 2024, Hinton shared the Nobel Prize in Physics with John Hopfield. The Royal Swedish Academy of Sciences recognized them for foundational discoveries and inventions that enable machine learning with artificial neural networks. These networks are inspired by the structure of the human brain. Hinton is also the first traditional computer scientist to win the Nobel Prize in Physics.

 AlexNet Changed Deep Learning Forever
AlexNet Changed Deep Learning Forever
In 2009, the ImageNet project provided large-scale annotated datasets, greatly promoting deep learning and computer vision research.
Before AlexNet, computer vision mainly relied on manually designed features like SIFT and HOG. Shallow learning models could only handle simple tasks. ImageNet had 1000 categories with 1000 images each. At that time, the error rate was 25 to 30 percent.
In 2012, Alex Krizhevsky, Ilya Sutskever, and Geoffrey Hinton published a paper at the NeurIPS conference. They proposed a deep convolutional neural network called AlexNet. It shocked the computer vision world by winning the ImageNet LSVRC-2010 image classification competition.

Paper link: https://proceedings.neurips.cc/paper/2012/file/c399862d3b9d6b76c8436e924a68c45b-Paper.pdf
Current citations: 188,837
Although deep learning concepts existed before, they faced three major obstacles. Limited data, gradient vanishing, and overfitting.
But the rise of GPUs, especially NVIDIA’s CUDA platform, provided the hardware foundation for training. AlexNet’s success proved that CNNs, combined with big data and powerful hardware support, could achieve breakthroughs. This opened the deep learning era.
AlexNet had 8 layers, including 5 convolutional layers and 3 fully connected layers. It had 60 million parameters and 650,000 neurons. It used ReLU activation, local response normalization, dropout regularization, and dual GPU training. These were all record-breaking at the time.
In testing, the Top-1 error rate was 37.5 percent and the Top-5 error rate was 17.0 percent. In the ILSVRC-2012 competition, the Top-5 error rate was 15.3 percent, far below the second place at 26.2 percent.
This paper marked the arrival of the deep learning era. It promoted CNNs as the core of computer vision and drove the transformation from traditional methods to deep learning.
AlexNet directly inspired later models like VGG and ResNet. It was widely applied in image classification, object detection, and face recognition. It also promoted GPU computing and large-scale datasets, pushing AI free ai porn maker research forward.
ai porn video generatorDeep Learning Review
By 2015, although deep learning had already shaken the academic world and appeared in broader scientific fields like Nature review articles, people still lacked systematic knowledge about why neural networks worked and what they lacked compared to traditional machine learning.
Before the deep learning explosion, a paper appeared in Nature that systematically answered what deep learning is. The full academic community finally understood.

Paper link: https://www.nature.com/articles/nature14539
Current citations: 107,646
This review deeply explained the key ideas behind deep learning’s breakthrough in traditional AI.
The paper summarized decades of exploration in representation learning, neural networks, and model training.
t-SNE Visualization
t-SNE or t-distributed Stochastic Neighbor Embedding was invented in 2008. It solved a major problem in data science. How to make complex high-dimensional data visible.
Before this, researchers mainly used linear methods like PCA or traditional probability embedding like SNE for dimensionality reduction. PCA performed poorly when preserving local structure. SNE had problems when mapping high-dimensional space to 2D or 3D. Nearby points in the original space would overlap and become impossible to distinguish.

Paper link: http://www.jmlr.org/papers/volume9/vandermaaten08a/vandermaaten08a.pdf
Current citations: 63,932
The core idea of t-SNE is to use Gaussian distribution in high-dimensional space to measure similarity between points. The probability of being chosen as a neighbor reflects similarity. In low-dimensional space, it uses Student t-distribution with one degree of freedom instead of Gaussian distribution. Because t-distribution has heavier tails than Gaussian distribution, it pushes distant points even farther apart in low-dimensional space. This effectively solves the crowding problem. Different data clusters become clearly separated.
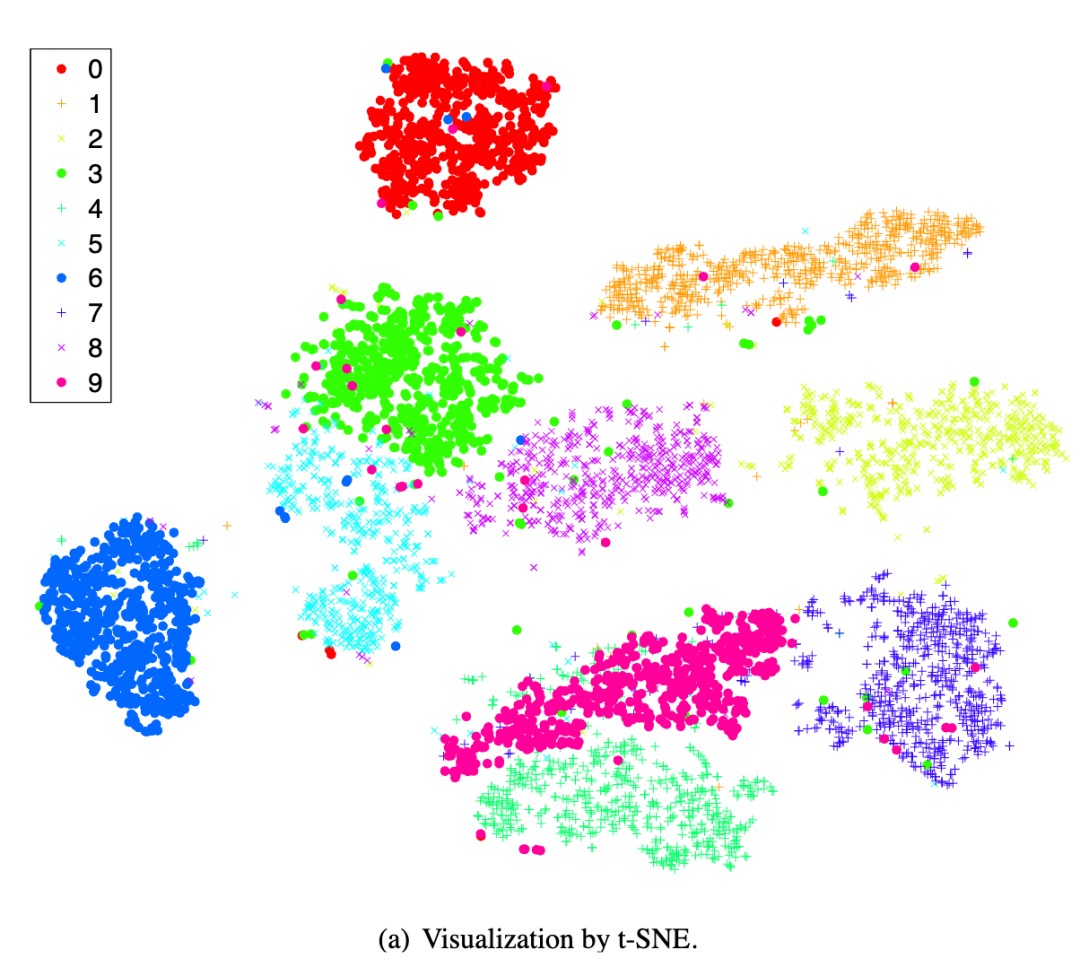
t-SNE quickly became the industry standard for high-dimensional data visualization. It was widely applied in observing model embeddings, extracting features, and visualizing clusters. From MNIST handwritten digits to gene cell classification, it helped researchers see patterns that were previously invisible.
Of course, t-SNE also has some limitations. For large-scale datasets, the computation speed is slow. Later versions like FIt-SNE were developed to address this. It preserves local structure well but does not guarantee complete global consistency. The algorithm is random, so different runs may produce different results.
 Dropout Prevents Overfitting
Dropout Prevents Overfitting
Paper link: https://dl.acm.org/doi/abs/10.5555/2627435.2670313
Current citations: 60,895
In 2014, deep neural networks achieved powerful modeling capabilities. They could fit complex functions while also suffering from overfitting. When training data is limited but model parameters are large, the model memorizes training samples including noise. When facing unknown data, performance drops sharply.
Although weight decay was used before, it was not enough. In addition, ensemble learning combines predictions from multiple different models to improve results. But this requires training multiple models independently, which is computationally expensive and impractical for deep neural networks.
Hinton proposed a very simple method called dropout. During training, the algorithm randomly drops hidden units with a certain probability, usually 0.5. This makes the network temporarily lose some neurons. It forces each hidden unit to learn more robust features. It reduces co-adaptation between neurons. It makes each neuron more independent and less reliant on specific other neurons.
From a mathematical perspective, dropout is essentially training a large number of thinned networks during training. During testing, it uses all neurons but with scaled weights. This achieves an approximate model averaging effect, improving generalization to unknown data.
Dropout was quickly applied to convolutional neural networks in computer vision. It significantly reduced overfitting in ImageNet classification tasks and became a standard technique in deep learning. It also proved that regularization techniques like data augmentation and weight decay could work together to produce more stable and reliable results.
Although in later developments, batch normalization and other techniques in some cases reduced the need for dropout, its underlying idea and its contribution to deep learning thinking remain important cornerstones of modern neural network optimization theory.
Once again, congratulations to Hinton. His persistence over decades has given AI to the world. And AI has given him a new legend.
CADOAN is a professional, independent AI industry blog and information platform dedicated to the research, sharing, and popularization of artificial intelligence. We are a team of AI enthusiasts, researchers, and technical writers who focus on the development and application of modern artificial intelligence. We do not represent any commercial institution, technology company, or AI model camp. Our only position is to provide real, objective, and valuable AI content for readers, learners, developers, and business practitioners around the world.