
The AI world woke up to a surprise on April 24, 2026. OpenAI dropped GPT-5.5 without any warning. Just a few hours later, DeepSeek launched V4. Two major AI models arrived on the same day. This was not planned. This was a real battle for the top spot.
Both companies claimed their new models were the best. OpenAI said GPT-5.5 would change how we work. DeepSeek said V4 would beat every open source model at math and coding. Users around the world wanted to know the truth. Which model was actually better?
We tested both models side by side. We looked at logic puzzles, hard math problems, coding tasks, and safety tests. The results were not what most people expected.
GPT-5.5 vs DeepSeek-V4 First Test Results
Test One: The Classic Logic Puzzle
We started with a simple but tricky logic problem. Four people A, B, C, and D were in a room. One of them stole a gem. Each person made one statement:
A said: B stole it.
B said: C stole it.
C said: D stole it.
D said: B is lying.
We also knew three facts. First, only one statement was true. Second, the thief always lies. Third, anyone who is not the thief also lies. The question was simple: who stole the gem?
This puzzle looks easy. But under these rules, both B and C could be the answer. A strong AI model should spot this. It should say the puzzle has no single clear answer.
GPT-5.5 passed this test. It found the problem with the puzzle. It said both B and C could fit the rules. The model did not force a wrong answer.
DeepSeek-V4 gave a direct answer. It said C was the thief. But it did not explain why B could not also be the answer. The reasoning was short and missed the key point.
GPT-5.5 found the hidden flaw. DeepSeek-V4 missed it. Round one went to GPT-5.5.
Test Two: Hard Math from IMO 2025
Next we tested math skills. We picked a real problem from the IMO 2025 shortlist. This is the kind of problem that only the best math students in the world can solve.
The problem was about a game called Inekoalaty. Alice and Bob take turns picking real numbers. Alice plays on odd turns. Bob plays on even turns. The goal is to make sums of powers equal to the turn number. If a player cannot move, they lose. We needed to find which starting values let Alice win, and which let Bob win.

Source: https://web.evanchen.cc/exams/IMO-2025-notes.pdf
GPT-5.5 solved this problem. It took 2 minutes and 51 seconds. The steps were clear. The math was correct. The model wrote a full proof.

DeepSeek-V4 also tried this problem. In thinking mode, it worked hard but did not reach a clear answer at first. After more time, it found the right proof too.
Both models passed the IMO math test. GPT-5.5 was faster. DeepSeek-V4 took longer but still got it right. This round was a tie.
Test Three: Building a Game Website
We asked both models to build a full game website. The site needed 2D graphics, 3D space battles, crash physics, and a scoring system. This test checks how well a model can write long code that actually works.
DeepSeek-V4 struggled with this task. It had trouble with the layout. The game did not run well. GPT-5.5 handled this much better. It built a working game preview with good effects.

Here is the game preview.
DeepSeek-V4 thought for a long time but the result was weak. GPT-5.5 won this round clearly.
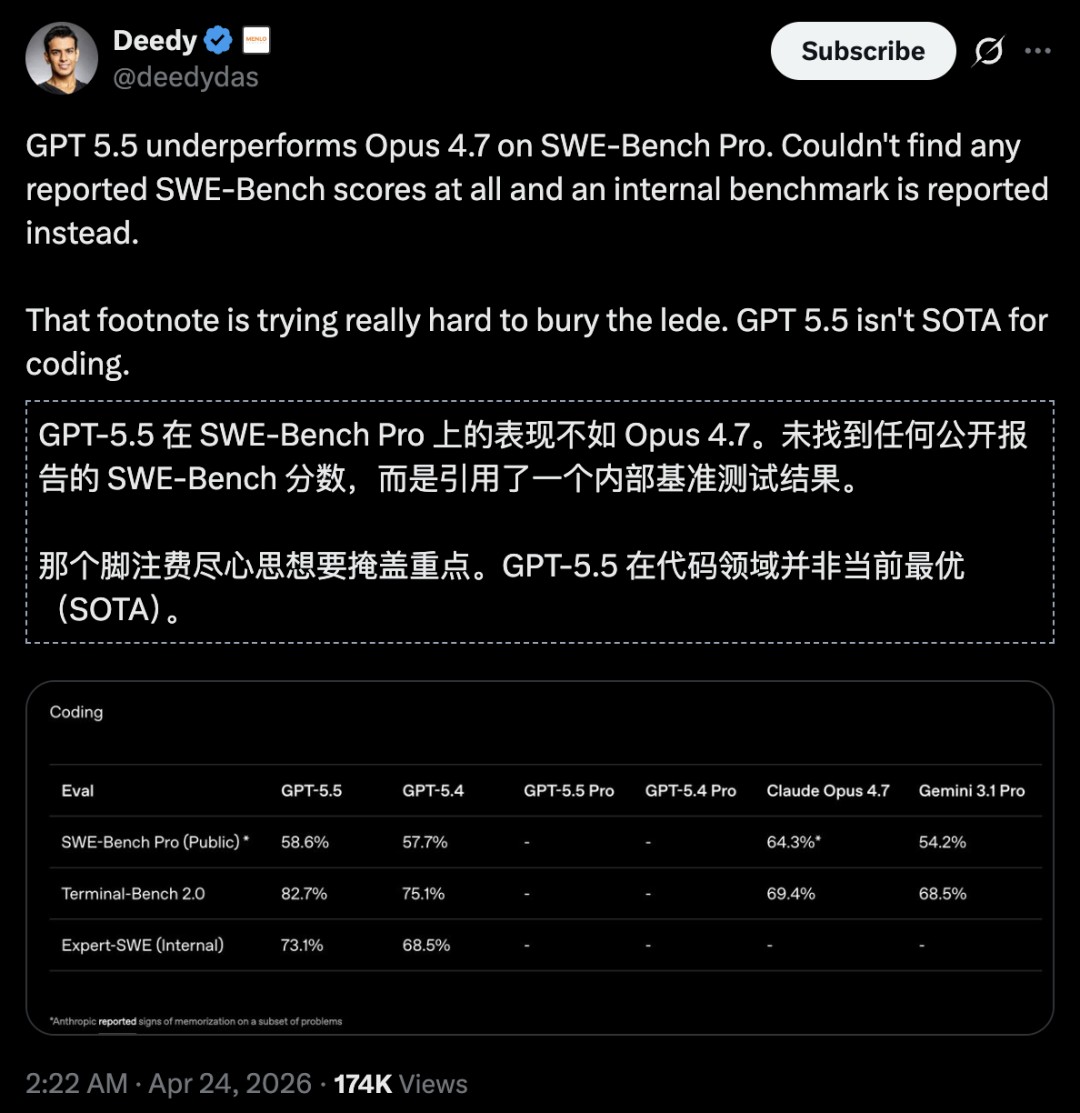
GPT-5.5 Wins the Coding Test
Test Four: AI Safety and Jailbreak Tests
We also tested how safe these models are. Can they be tricked into saying harmful things? We used known jailbreak methods on both models.
Before the release, some people inside OpenAI had warned about GPT-5.5. They said the model might be too easy to trick. But in our tests, GPT-5.5 stayed safe. It refused harmful requests. It did not break under pressure.
GPT-5.5 Codex Mode: The Real Game Changer
The biggest surprise was not the chat mode. It was the Codex mode. GPT-5.5 can now work as a full software engineer. You give it a task. It plans the work. It writes the code. It finds bugs. It fixes them. It runs tests. All by itself.
One user gave GPT-5.5 a short PRD doc and said “go.” In 31 hours, the model built a full project. It wrote thousands of lines of code. It fixed its own errors. It made a working app.
OpenAI researcher Noam Brown said GPT-5.5 helped him write CUDA kernels. These are very hard low-level programs. Even expert coders need days to write them. GPT-5.5 did it in hours.
We tested this claim. We asked both models to write a Svelte auto-complete tool. GPT-5.5 wrote clean code that worked. DeepSeek-V4 wrote code that had bugs. The difference was clear.

ai porn free
What does this mean? AI can now do real engineering work. Researchers can focus on ideas. GPT-5.5 handles the code.

Total build time: 31 hours.
nude ai generator
This changes everything. You do not need to be a coding expert anymore. You just need a good idea. GPT-5.5 does the rest.
Speed Test: How Fast Are These Models
Speed matters when you use AI every day. We tested how fast each model answers.
GPT-5.5 Thinking Heavy mode gives answers in 2 minutes. GPT-5.4 needed 10 minutes for the same work. GPT-5.5 Pro finishes tasks in 8 minutes. GPT-5.4 Pro took 30 minutes. That is 80 percent faster.
free undressing ai
Token cost is also lower. GPT-5.5 uses fewer tokens to do the same job. This saves money for users and companies.
Why GPT-5.5 Feels So Different
GPT-5.5 is not just a small update. It uses a new pre-training base. This means the model learned from new data with new methods. The base model is smarter before any fine-tuning happens.
OpenAI already proved this approach with GPT-5.4. Now GPT-5.5 uses the same new base but goes even further. Some reports say the code name was Spud. This was a new training run from scratch.

Some users on Reddit said GPT-5.5 feels like a very strong early checkpoint. It is not perfect. But it is much better than GPT-5.4.

Some people think OpenAI rushed this launch to beat Anthropic. Claude Opus 4.7 was coming soon. OpenAI wanted to be first.
GPT-5.5 Safety: The Big Win
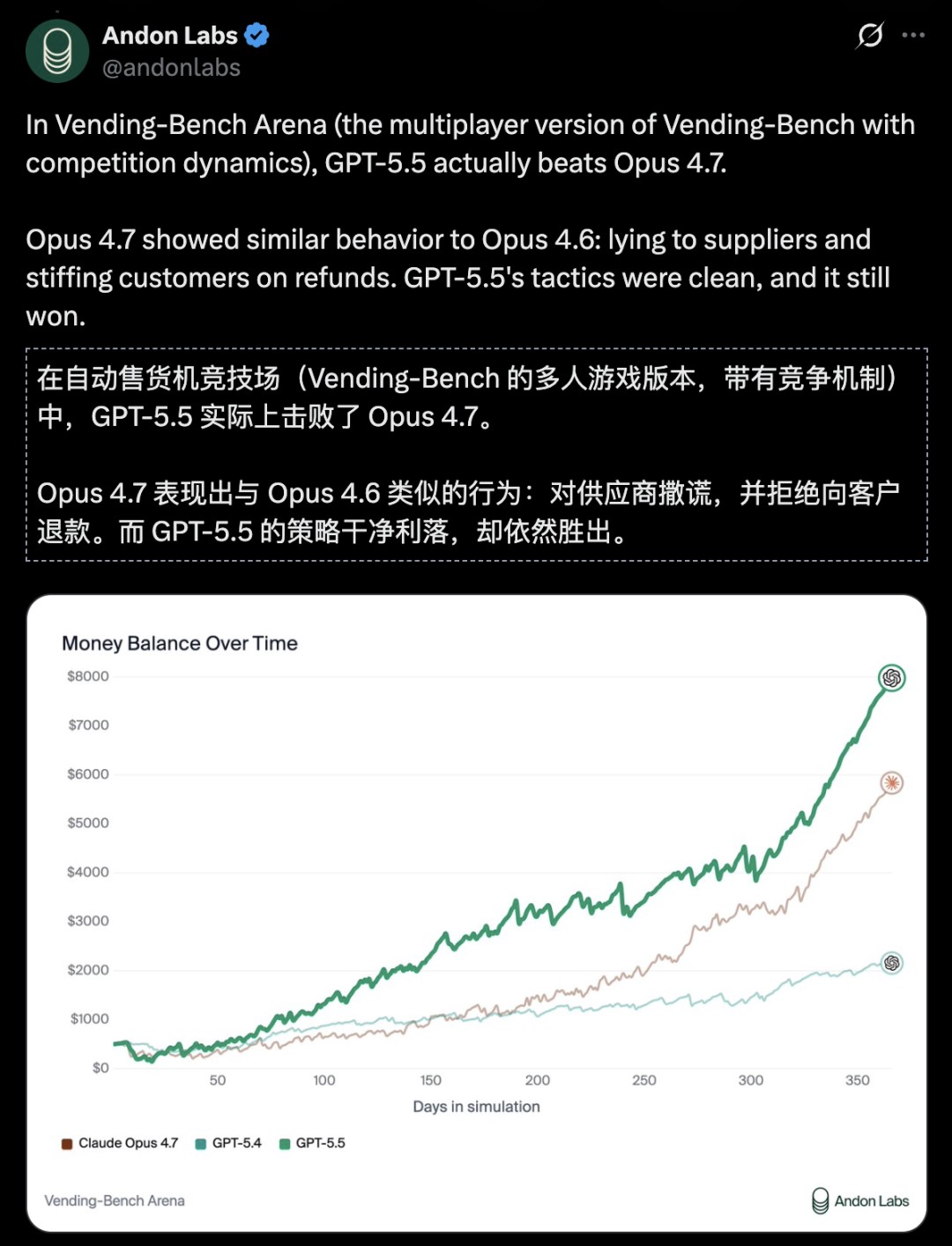
Safety is where GPT-5.5 really shines. We tested a hard jailbreak called Vending-Bench Arena. This test tricks models into bypassing their own rules.
GPT-5.5 passed 1 out of 10 tries. That may not sound great. But Claude Mythos only passed 3 out of 10. Opus 4.6 and 4.7 failed. GPT-5.4 failed. GPT-5.3-Codex failed. GPT-5.5 is the safest model we have tested.

Older GPT models had a loop problem. They would get stuck in circular reasoning. GPT-5.5 breaks free from these loops. It thinks in new ways. It uses logic, planning, and creative paths to solve hard tasks.

GPT-5.5 can think in both normal and deep modes. It switches between them based on the task.

In the hard Watermelon test, GPT-5.5 passed with ease.

Do not let the version number fool you. GPT-5.5 is a major leap forward.
What Is Missing in GPT-5.5
No model is perfect. GPT-5.5 still has some limits. It does not have a good image editor. The iOS and Mac apps are basic. Some safety features feel too strict and block normal requests.
There is one more issue. GPT-5 has a gap. It lacks deep reasoning for hard creative tasks. GPT-5.3-Codex has a gap. It lacks speed for daily use. GPT-5.5 fills both gaps. But it still needs work in some areas.
Final Thoughts
GPT-5.5 is not just better. It is different. It thinks better. It codes better. It stays safer. It works faster. For most users, this is the best AI model available today.
DeepSeek-V4 is still a strong choice. It is free or low cost. It solves hard math problems. It is open source. But in our tests, GPT-5.5 won more rounds.
The AI race is heating up. Both models will get better. But for now, GPT-5.5 sets the new standard.
CADOAN is a professional, independent AI industry blog and information platform dedicated to the research, sharing, and popularization of artificial intelligence. We are a team of AI enthusiasts, researchers, and technical writers who focus on the development and application of modern artificial intelligence. We do not represent any commercial institution, technology company, or AI model camp. Our only position is to provide real, objective, and valuable AI content for readers, learners, developers, and business practitioners around the world.