
Gemini is backed by Google, equipped with top-tier talent and enormous computing power — so why does it keep getting worse with every update? Gemini 3.1 suffers from abysmal instruction adherence, poor focus, and drastically truncated context retention. It often overlooks detailed prompts, misses key requirements, and struggles to sustain long conversational context, frequently forgetting earlier dialogue and user preferences. This leads to off-topic responses, inconsistent reasoning, and repeated failure to follow predefined rules and formatting constraints.
It’s Not About Talent or GPUs—It’s About How They’re Used
Google has world‑class TPUs, DeepMind, and huge budgets. But resources don’t equal effective investment,Among the three universally recognized top-tier players in the large language model space — OpenAI with its GPT series, Anthropic with Claude, and Google with Gemini — Google’s Gemini boasts the lowest barrier to entry. It even offers free access through student verification programs.
However, as its user base skyrockets, inference costs have surged dramatically. To cut expenses, Google has quietly scaled back the model’s overall intelligence: it has reduced reasoning steps, lowered response precision, and rerouted traffic to cheaper, smaller model variants during peak usage hours.
| Metric | 2026 Data | Source |
|---|---|---|
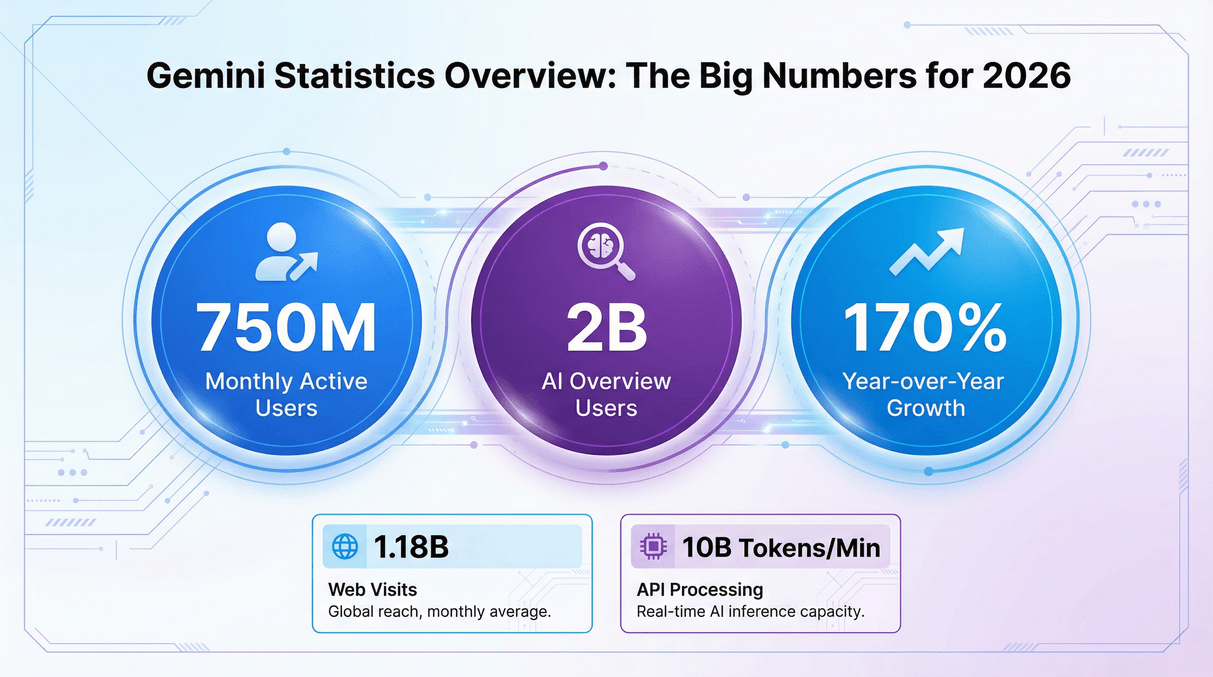
| Monthly Active Users (App) | Approximately 750 million | TechCrunch |
| Daily Active Users (App) | 35 million (April 2025) | TechCrunch |
| AI Overview Monthly Search Users | Approximately 2 billion per month | FatJoe |
| Website Traffic (gemini.google.com) | 1.18 billion (October 2025) | ElectroIQ |
| Average Session Duration | 6–7 minutes | ElectroIQ |
| US Mobile Downloads | 1.3 million (March 2025) | ElectroIQ |
| API Throughput | 10 billion tokens per minute | TechCrunch |
| Year-over-Year Monthly Active User Growth | Approximately 170% (rose from 350 million to 750 million in 12 months) | FatJoe |
Gemini has an enormous user base, and people from all over the world use Google Search to access its AI Overviews.
Existing Problems of Gemini
- Imbalanced Cost Control: “Dumbing Down” After Launch, Continuous Experience Deterioration: In the early stage of the launch of new Gemini versions (such as Gemini 3.x), they will present impressive benchmark performance and high-quality experience relying on full-configured computing power. However, 1-3 months after the launch, as the number of users surges, Google will forcibly “downgrade” the model to control inference costs: it will force the model to output shorter and simpler content through system prompts, lock in low-level reasoning parameters, and even switch to lightweight, low-quality versions during peak hours. This directly leads to user feedback of increased model hallucinations, weakened logical capabilities, and frequent disregard of user instructions.
- Excessive Safety Alignment: “Safety Costs” Sacrifice Core Intelligence: Compared with peers, Google has extremely strict even paranoid requirements on the model’s safety compliance and political correctness. The layers of content filtering, bias control, and fact-checking mechanisms not only consume a lot of computing power but also severely limit the model’s creativity and reasoning depth. Eventually, Gemini deliberately avoids in-depth thinking, only outputs safe but empty content, and dare not take any intellectual risks. In contrast, GPT and Claude can still maintain bold reasoning capabilities.
-
Confused Product Strategy: Jack of All Trades, Master of None, Vague Positioning: Gemini’s product positioning has always been volatile. It wants to serve as a search assistant, while also taking on multiple roles such as chatbot, code assistant, and lightweight mobile AI; at the same time, it advances multiple directions in parallel, including multimodality, long context, and on-device deployment, resulting in severe resource dispersion. In contrast, GPT focuses on dialogue and coding, Claude excels in long text processing and reasoning, while Gemini pursues “all-round capabilities” and ultimately falls into the dilemma of “being jack of all trades but master of none, mediocre everywhere.”
-
Weak Engineering Implementation: Disconnection Between Lab Performance and Actual Experience: Google overvalues academic benchmarks but neglects product stability and practical usability, leading to many engineering problems in Gemini: severe hallucinations, frequent false sources and data errors; frequent mistakes in basic logic and mathematical calculations; the advertised 1 million token long-context function is virtually useless, with malfunctions occurring when exceeding 200k tokens and complete inoperability at 500k tokens; at the same time, the dialogue tone is mechanical and rigid, lacking empathy, and it is difficult to understand the user’s subtext.
-
Exaggerated Benchmark Tests: Huge Gap Between Publicity and Actual Capabilities: Gemini performs overwhelmingly in standardized benchmark tests such as MMLU and MMMU, but this advantage is mostly derived from targeted optimization and even deliberate benchmark manipulation. In real application scenarios, whether it is writing, coding, or problem-solving, Gemini’s performance is far inferior to the promotional effect. Users generally feedback that it is “impressive in demos but poor in actual use,” with a serious disconnection between lab performance and daily experience.
CADOAN is a professional, independent AI industry blog and information platform dedicated to the research, sharing, and popularization of artificial intelligence. We are a team of AI enthusiasts, researchers, and technical writers who focus on the development and application of modern artificial intelligence. We do not represent any commercial institution, technology company, or AI model camp. Our only position is to provide real, objective, and valuable AI content for readers, learners, developers, and business practitioners around the world.
No Comments